特定の文書ドキュメントを抽出
<< エクセルVBAで開いているページのURLを抽出する :前の記事
前回は、URLプロパティとLocationURLプロパティを利用して開いているページのURL(アドレス)を取得する方法について解説しました。最後にどの処理が一番速いかを計測しましたが、処理回数が多い場合はInternetExplorerオブジェクトのLocationURLプロパティが一番速いことが分かりました。今回は、HTMLドキュメント内の特定の文書ドキュメントを取得する方法について解説していきます。
目次
- DOM(Document Object Model)とは
- HTML(HyperText Markup Language)とは
- タグと要素(エレメント)の違い
- 要素を特定するプロパティ・メソッドの使い分けについて
- 文書ドキュメント取得の計測結果
- 文書ドキュメント取得の処理の考え方
- まとめ
DOM(Document Object Model)とは
DOMとは「Document Object Model」の略称で、html・head・body・p・aなどのHTMLドキュメント要素にアクセスして取得や操作ができる仕組みのことです。
以下はHTMLドキュメントをツリー構造に表したものでDOMツリーと呼ばれます。階層状のツリー構造でHTMLドキュメントを表現します。
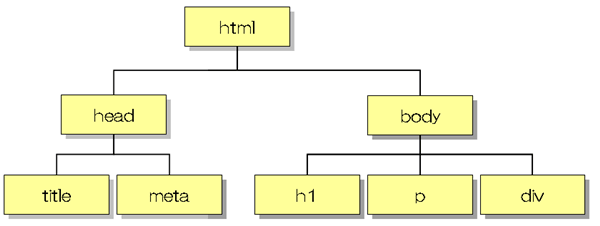
HTML(HyperText Markup Language)とは
HTMLとは「HyperText Markup Language」の略称で、Webページを作成するために開発された言語です。世の中に公開されているWebページのほとんどがHTMLで作成されています。こちらのサイトもHTMLで作成されています。
HTMLは基本的に以下のような構成でできており「<タグ名>★テキスト★</タグ名>」が1つの要素(エレメント)になります。この中の特定の要素に対してデータの取得や操作を行っていきます。
<html>
<head>
<title>VBAのIE制御</title>
</head>
<body>
<p>こちらはpタグのテキストです。</p>
<a href="★リンクURL(アドレス)★">リンクのアンカーテキストです。</a>
</body>
</html>タグと要素(エレメント)の違い
HTML言語では、「タグ」と呼ばれる仕組みを利用して構築していきます。以下のイメージを確認すると分かりやすいと思いますが、タグとは「<」と「>」で構成されており、開始タグと終了タグまでの括りで1つの要素を形成します。
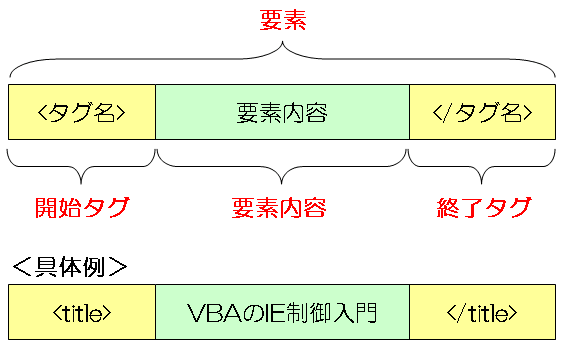
具体例で説明するとWebページのURL(アドレス)を表す「titleタグ」を利用して開始タグの「<title>」と終了タグの「</title>」で括り、タグの中の文字列が「要素内容」となります。こちらでは「VBAのIE制御入門」の文字列が要素内容となります。
そして、こちらの「開始タグ+要素内容+終了タグ」の全体を「要素」と呼びます。また、別名では「エレメント」と呼ばれますので、どちらも同じ意味であることを理解してください。
要素を特定するプロパティ・メソッドの使い分けについて
「HTMLエレメント基本操作」では、以下のような要素を特定するプロパティやメソッドを紹介してきましました。
- Allプロパティ
- getElementByIdメソッド
- getElementsByNameメソッド
- getElementsByClassNameメソッド
- getElementsByTagNameメソッド
今回はこちらを利用して文書ドキュメントを抽出する方法を解説しますが、どのような使い分ければよいかということを考えていきます。「HTMLエレメント基本操作」では何度も「特定の要素オブジェクトをどのような道筋で取得するかがポイント」であると説明してきました。
要素を特定するには上記で紹介したようなプロパティやメソッドを利用しますが、どの道筋を辿ったとしても結果は同じです。「どのように使い分けるか」というのは「どのように効率よく(速く)抽出できるか」という意味合いで説明していきます。
そこで、まずはどのプロパティやメソッドが一番処理が速いのかを検証してみます。
文書ドキュメント取得の計測結果
まず、計測する処理は以下の5つになります。それぞれの処理内容については「HTMLエレメント基本操作」で説明していますので割愛しますが、全て同じ値を抽出します。
Sub sample()
Dim objIE As InternetExplorer
Dim objDoc As HTMLDocument
'IE(InternetExplorer)でテストページを起動する
Call ieView(objIE, "http://www.vba-ie.net/code/all.html")
'①Allプロパティでid属性を指定して抽出する
MsgBox objIE.document.all("idtest").innerText
'②getElementByIdメソッドで抽出する
MsgBox objIE.document.getElementById("idtest").innerText
'③getElementsByNameメソッドで抽出する
For Each objDoc In objIE.document.getElementsByName("nametest")
If InStr(objDoc.outerHTML, "一番速い処理はどれ?") > 0 Then
MsgBox objDoc.innerText
Exit For
End If
Next
'④getElementsByClassNameメソッドで抽出する
For Each objDoc In objIE.document.getElementsByClassName("classtest")
If InStr(objDoc.outerHTML, "一番速い処理はどれ?") > 0 Then
MsgBox objDoc.innerText
Exit For
End If
Next
'⑤getElementsByTagNameメソッドで抽出する
For Each objDoc In objIE.document.getElementsByTagName("p")
If InStr(objDoc.outerHTML, "一番速い処理はどれ?") > 0 Then
MsgBox objDoc.innerText
Exit For
End If
Next
End Sub取得するHTMLコード
<p id="idtest" name="nametest" class="classtest">一番速い処理はどれ?</p>
以下は上記の各処理を5000回繰り返し処理をした時間を計測したものです。
| 回数・処理 | 処理① | 処理② | 処理③ | 処理④ | 処理⑤ |
|---|---|---|---|---|---|
| 1回目 | 7.9766秒 | 8.2512秒 | 49.5736秒 | 52.3651秒 | 83.6541秒 |
| 2回目 | 7.5508秒 | 7.9564秒 | 49.6854秒 | 52.4694秒 | 84.6235秒 |
| 3回目 | 6.2773秒 | 7.8451秒 | 47.6251秒 | 51.9584秒 | 82.6541秒 |
| 4回目 | 6.5241秒 | 8.0215秒 | 50.5132秒 | 53.5164秒 | 83.6594秒 |
| 5回目 | 7.1254秒 | 8.1265秒 | 49.6842秒 | 51.5461秒 | 84.6231秒 |
| 平均 | 7.0908秒 | 8.0401秒 | 49.4165秒 | 52.3710秒 | 83.8428秒 |
まず、処理①②が他の処理より群を抜いて速いのは、ループ処理を行っていないことが挙げられます。処理①②は共にid属性を指定して特定の要素を取得する処理になります。
「id属性の要素を取得するGetElementByIdメソッド」でも説明しましたが、HTMLのルール上id属性は要素を識別するために一意のid名にする必要があるため同じページに同じid名を利用することはできません。ですので、id属性で要素を取得する場合はループ処理を行う必要がないため、他の処理より速く取得できます。
処理①②を比べると処理①のAllプロパティの方が若干処理は速いですが、「meta要素のkeywordsとdescriptionを抽出する」で説明したように取得する位置によって処理速度が変わるのでgetElementByIdメソッドを利用した方が処理は安定します。
次に処理③④⑤を見ると処理⑤がダントツで遅いことが分かります。処理⑤のgetElementsByTagNameメソッドはwebスクレイピングでよく利用するメソッドですが、うまく利用しなければ無駄に処理時間がかかってしまう恐れがありますので注意が必要です。それでは、次に今回の検証を踏まえてどのように使い分けていくかを考えていきます。
文書ドキュメント取得の処理の考え方
文書ドキュメント取得の処理について箇条書きにすると以下のような流れになります。一度こちらを確認してから読み進めてください。
- ①HTMLソースを確認する。
- ②抽出する文書ドキュメントのタグ名と設定している属性を確認する。
- ③id属性がある場合は、getElementByIdメソッドで処理をする。
- ④id属性がない場合は、親要素・子要素にid属性がないか確認する。
- ⑤親要素・子要素にid属性がある場合は、parentElementプロパティ・Childrenプロパティを利用して抽出する要素を特定する。
- ⑥親要素・子要素にid属性がない場合は、name属性とタグ名の組み合わせが一意かどうかを確認する。
- ⑦name属性とタグ名の組み合わせが一意の場合は、getElementsByNameメソッドとnodeNameプロパティを利用して抽出する要素を特定する。
- ⑧name属性とタグ名の組み合わせが一意でない場合は、class属性とタグ名の組み合わせが一意かどうかを確認する。
- ⑨class属性とタグ名の組み合わせが一意の場合は、getElementsByClassNameメソッドとgetElementsByTagNameメソッドを利用して抽出する要素を特定する。
- ⑩class属性とタグ名の組み合わせが一意でない場合は、要素内に一意のキーワードがないか確認する。
- ⑪要素内に一意のキーワードがある場合は、getElementsByTagNameメソッドと一意のキーワードを利用して抽出する要素を特定する。
- ⑫要素内に一意のキーワードがない場合は、複数の処理を組み合わせて抽出する要素を特定する。
①HTMLソースを確認する。
まずは、処理をするページのHTMLソースを読み解く作業から開始します。webスクレイピングで複数ページをループ処理で取得する場合は、どのページでも共通の部分が存在することが多いです。その部分を読み解いてループ処理を行いデータを抽出していきます。
HTMLソースを読み解くにはHTMLの知識があったほうが理解しやすいですが、そうでない方は以下の処理の流れを理解すればほとんどのデータは抽出できるかと思います。
②抽出する文書ドキュメントのタグ名と設定している属性を確認する。
抽出したい文書ドキュメントのタグ名と要素内に設定してあるid属性・name属性・class属性を確認します。属性については、必ず設定されているものではないので、設定の有無を確認してください。
<p id="idtest" name="nametest" class="classtest">抽出したい要素</p>
<p name="nametest2">設定されていない属性もあります</p>
③id属性がある場合は、getElementByIdメソッドで処理をする。
タグ名と設定している属性を確認したら、最初にid属性をチェックします。id属性が設定されている場合は、迷わずgetElementByIdメソッドを利用して抽出を行います。
処理速度の検証でも確認したようにループ処理で抽出するより直接要素を指定した方が処理速度が速いので最初にid属性を確認して、id属性がある場合はgetElementByIdメソッドで処理をしましょう。
<p id="idtest">抽出したい要素</p>
MsgBox objIE.document.getElementById("idtest").innerText④id属性がない場合は、親要素・子要素にid属性がないか確認する。
id属性がない場合は、抽出する要素の親要素・子要素にid属性がないか確認してください。こちらは処理が遅いループ処理を行わずに抽出させるための確認です。親要素・子要素にid属性がある場合は、間接的に抽出する要素を指定します。親要素・子要素の取得については「指定した要素に対して親要素と子要素を取得する」で解説していますので確認してください。
<div id="idparent">
<p>****</p>
<p>抽出したい<span id="idchild">要素</span></p>
<p>****</p>
</div>
⑤親要素・子要素にid属性がある場合は、parentElementプロパティ・Childrenプロパティを利用して抽出する要素を特定する。
親要素・子要素にid属性がある場合は、まず親要素あるいは子要素を取得してから抽出する要素を指定してデータを抽出します。これによりループ処理を行わずに、抽出することができます。
<div id="idparent">
<p>****</p>
<p>抽出したい<span id="idchild">要素</span></p>
<p>****</p>
</div>
こちらの処理はdiv要素にid属性「idparent」が設定されていますので、まずgetElementByIdメソッドでdiv要素を取得してからChildrenプロパティを利用して子要素である抽出したいp要素を指定しています。Childrenプロパティの添え字に「1」を設定していますので、2番目の子要素を指定していることになります。
ただし、こちらは親要素のすぐ近くに抽出したい要素がある場合に利用してください。添え字が10番台以上になると数えるのも大変ですのでその場合は他の方法で抽出していきます。
MsgBox objIE.document.getElementById("idparent").Children(1).innerTextこちらの処理はspan要素にid属性「idchild」が設定されていますので、まずgetElementByIdメソッドでspan取得をしてからparentElementプロパティを利用して親要素である抽出したいp要素を指定しています。
MsgBox objIE.document.getElementById("idchild").parentElement.innerText⑥親要素・子要素にid属性がない場合は、name属性とタグ名の組み合わせが一意かどうかを確認する。
親要素・子要素にid属性がない場合は、name属性とタグ名の組み合わせが一意かどうかを確認します。「一意」というのは、他に同じものがなく1つしかないことを指します。
name属性はページ内で同じ名前のものを何度でも利用してもよいことになっています。仮に同じname属性が存在した場合は、どちらかを判断するために更に処理が必要となりますので、ここでは1つしかない組み合わせを探していきます。
以下の事例で言えばname属性「nametest2」の要素はいくつか存在しますが、name属性「nametest2」のp要素は1つしか存在しませんので、name属性「nametest2」のp要素は「一意」と判断します。
<p name="nametest1">****</p>
<div name="nametest2">****</div>
<div name="nametest2">****</div>
<p name="nametest2">抽出したい要素</p>
<p name="nametest1">****</p>
⑦name属性とタグ名の組み合わせが一意の場合は、getElementsByNameメソッドとnodeNameプロパティを利用して抽出する要素を特定する。
name属性とタグ名の組み合わせが一意の場合は、For Each~Nextステートメントを利用して、ループ処理で抽出したい要素を指定します。また、For Each~Nextステートメントのループ対象はgetElementsByNameメソッドで取得した要素コレクションになります。
<p name="nametest1">****</p>
<div name="nametest2">****</div>
<div name="nametest2">****</div>
<p name="nametest2">抽出したい要素</p>
<p name="nametest1">****</p>
こちらは実際の処理の内容です。getElementsByNameメソッドに「nametest2」を設定してid属性「nametest2」のコレクションを取得しています。こちらをFor Each~Nextステートメントのコレクションに設定し、id属性「nametest2」の要素数だけループ処理を行っています。
次にIf~Then~Elseステートメントを利用してid属性「nametest2」のタグ(ノード)の名前が「p」の場合に要素を抽出します。
タグ(ノード)の名前を取得するにはnodeNameプロパティを利用しますが、LCase関数でタグ(ノード)を小文字に変換しています。ここまで確認した中ではnodeNameプロパティは大文字で返すのですが、イレギュラーを排除するために念のため小文字に変換しています。
For Each objDoc In objIE.document.getElementsByName("nametest2")
If LCase(objDoc.nodeName) = "p" Then
MsgBox objDoc.innerText
Exit For
End If
Nextこちらの処理は一般的に利用されている処理で、よく目にするのではないでしょうか。処理の内容を簡単に説明するとまずgetElementsByTagNameメソッドでp要素のコレクションを取得してから要素内に一意のキーワード「nametest2」が含まれている場合に要素を抽出する処理になります。
こちらでも抽出することは可能ですが、上記の処理と処理速度を比較してみると差は歴然です。
For Each objDoc In objIE.document.getElementsByTagName("p")
If InStr(objDoc.outerHTML, "nametest2") > 0 Then
Debug.Print objDoc.innerText
Exit For
End If
NextこちらがgetElementsByNameメソッドとgetElementsByTagNameメソッドで処理した処理速度の計測結果です。指定したname属性の要素コレクションをループ処理させた方が、約5倍も処理が速いことが分かります。
よって、name属性とタグ名の組み合わせが一意の場合は、getElementsByNameメソッドとnodeNameプロパティを利用するようにしましょう。
| 回数・処理 | getElementsByName | getElementsByTagName |
|---|---|---|
| 1回目 | 24.9571秒 | 130.6484秒 |
| 1回目 | 25.3398秒 | 129.8164秒 |
⑧name属性とタグ名の組み合わせが一意でない場合は、class属性とタグ名の組み合わせが一意かどうかを確認する。
name属性とタグ名の組み合わせが一意でない場合は、class属性とタグ名の組み合わせが一意かどうかを確認します。以下の事例で言えばclass属性「classtest2」の要素はいくつか存在しますが、class属性「classtest2」のp要素は1つしか存在しませんので、class属性「classtest2」のp要素は「一意」と判断します。
<p class="classtest1">****</p>
<div class="classtest2">****</div>
<div class="classtest2">****</div>
<p class="classtest2">抽出したい要素</p>
<p class="classtest1">****</p>
⑨class属性とタグ名の組み合わせが一意の場合は、getElementsByClassNameメソッドとgetElementsByTagNameメソッドを利用して抽出する要素を特定する。
class属性とタグ名の組み合わせが一意の場合は、For Each~Nextステートメントを利用して、ループ処理で抽出したい要素を指定します。また、For Each~Nextステートメントのループ対象はgetElementsByClassNameメソッドで取得した要素コレクションになります。
<p class="classtest1">****</p>
<div class="classtest2">****</div>
<div class="classtest2">****</div>
<p class="classtest2">抽出したい要素</p>
<p class="classtest1">****</p>
こちらは実際の処理の内容です。getElementsByClassNameメソッドに「classtest2」を設定してclass属性「classtest2」のコレクションを取得しています。こちらをFor Each~Nextステートメントのコレクションに設定し、class属性「classtest2」の要素数だけループ処理を行っています。
次にIf~Then~Elseステートメントを利用してclass属性「classtest2」のタグ(ノード)の名前が「p」の場合に要素を抽出します。
For Each objDoc In objIE.document.getElementsByClassName("classtest2")
If LCase(objDoc.nodeName) = "p" Then
MsgBox objDoc.innerText
Exit For
End If
Nextこちらも一般的な処理と処理速度を比較すると以下のようになります。class属性とタグ名の組み合わせが一意の場合は、getElementsByClassNameメソッドとnodeNameプロパティを利用するようにしましょう。
For Each objDoc In objIE.document.getElementsByTagName("p")
If InStr(objDoc.outerHTML, "classtest2") > 0 Then
Debug.Print objDoc.innerText
Exit For
End If
Next| 回数・処理 | getElementsByName | getElementsByClassName |
|---|---|---|
| 1回目 | 24.8516秒 | 139.5469秒 |
| 1回目 | 24.9854秒 | 137.8492秒 |
⑧class属性とタグ名の組み合わせが一意でない場合は、要素内に一意のキーワードがないか確認する。
class属性とタグ名の組み合わせが一意でない場合は、要素内に一意のキーワードがないかを確認します。「要素内に一意のキーワード」というのは、抽出したい要素データ内で他とまったく被らないキーワードであればどのようなキーワードでも構いません。
例えばあるECサイトの商品情報で以下のようなHTMLコードであったとします。この中から販売価格を抽出したい場合、id・name・class属性はなにも設定されていませんので、「一意のキーワード」を探していきます。
この中で言えば「円(税込)」というキーワードは他の商品ページでも同様に利用され他ではほぼ記述されないキーワードですので、こちらを「一意のキーワード」とします。万が一、商品紹介の中で金額を記述している場合を考慮したい場合は「円(税込)</td>」までを「一意のキーワード」としても構いません。
<table>
<tr>商品名</th><td>商品A</td></tr>
<tr>販売価格</th><td>1,500円(税込)</td></tr>
<tr>カラー</th><td>ブラック、ホワイト、レッド</td></tr>
<tr>サイズ</th><td>32*25cm</td></tr>
</table>
⑨要素内に一意のキーワードがある場合は、getElementsByTagNameメソッドと一意のキーワードを利用して抽出する要素を特定する。
要素内に一意のキーワードがある場合は、For Each~Nextステートメントを利用して、ループ処理で抽出したい要素を指定します。また、For Each~Nextステートメントのループ対象はgetElementsByTagNameメソッドで取得した要素コレクションになります。
<table>
<tr>商品名</th><td>商品A</td></tr>
<tr>販売価格</th><td>1,500円(税込)</td></tr>
<tr>カラー</th><td>ブラック、ホワイト、レッド</td></tr>
<tr>サイズ</th><td>32*25cm</td></tr>
</table>
こちらは実際の処理の内容です。getElementsByTagNameメソッドに「p」を設定して「p要素」のコレクションを取得しています。こちらをFor Each~Nextステートメントのコレクションに設定し、p要素の要素数だけループ処理を行っています。
次にIf~Then~Elseステートメントを利用して要素内に一意のキーワードの「円(税込)」が含まれている場合に要素を抽出します。
「一意のキーワード」が含まれているかの確認は、指定したキーワードで最初に見つかった文字位置を返すInStr関数を利用しています。キーワードが含まれている場合は必ず「0」以上の値を返すので、比較演算子を利用して「0」以上の場合を条件式としています。
For Each objDoc In objIE.document.getElementsByTagName("p")
If InStr(objDoc.outerHTML, "円(税込)") > 0 Then
Debug.Print objDoc.innerText
Exit For
End If
Nextこちらの処理が一番遅い処理になりますので、なるべく処理の速い方法で対応するようにしましょう。ただし、こちらは多くの処理を行うwebスクレイピングの場合で有効な方法ですので、例えばあるサービスの自動ログイン処理であったり、処理そのものの時間が短い場合はどれを選んでもさほど大差はないかと思います。
⑫要素内に一意のキーワードがない場合は、複数の処理を組み合わせて抽出する要素を特定する。
「一意のキーワード」がない場合やアクセスする毎に値が変更になる場合は、これまでの処理をうまく組み合わせて処理をするようにしましょう。こちらは特に事例はありませんが、どうしてもできない場合は「VBAのIE制御についてのQ&掲示板」で質問してみるのも1つの手です。有志の方が教えてくれるかもしれません。
まとめ
今回は、HTMLドキュメント内の特定の文書ドキュメントを取得についていくつかの方法を解説しました。多くの処理を行うwebスクレイピングの場合、適切な処理を選択しなければかなり時間がかかってしまいます。こちらを理解したい上で臨機応変に対応するようにしましょう。
次回は、こちらで紹介した処理でid属性を指定して文書ドキュメントを抽出するサブルーチンの作成について解説していきます。
次の記事: エクセルVBAでid属性を指定して文書ドキュメントを抽出するサブルーチン >>

近田 伸矢, 植木 悠二, 上田 寛
IEのデータ収集&自動操作のプログラミング本はこの1冊だけ!IEの起動やポップアップウィンドウ、表示を制御する基本的なコードはもちろん、テキストボックスやラジオボタン、表、ハイパーリンクなどのHTML部品を制御する方法など、自動操作に欠かせないノウハウを丁寧に解説。

- ツイート
